ЙиСЊЙцдђдкХЉвЕаХЯЂЭкОђжаЕФгІгУбаОП(ИНД№Бч)
РДдДЃКwenku7.com зЪСЯБрКХЃКWK73170 зЪСЯЕШМЖЃКЁяЁяЁяЁяЁя %E8%B5%84%E6%96%99%E7%BC%96%E5%8F%B7%EF%BC%9AWK73170
вдЯТЪЧзЪСЯНщЩм,ШчашвЊЭъећЕФЧыГфжЕЯТдиЁЃ
1.ЮоашзЂВсЕЧТМ,жЇИЖКѓАДееЬсЪОВйзїМДПЩЛёШЁИУзЪСЯ.
2.зЪСЯвдЭјвГНщЩмЕФЮЊзМ,ЯТдиКѓВЛЛсгаЫЎгЁ.зЪСЯНіЙЉбЇЯАВЮПМжЎгУ. Ум БЃ Лн Аяжњ
зЪСЯНщЩм
ЙиСЊЙцдђдкХЉвЕаХЯЂЭкОђжаЕФгІгУбаОП(ИНД№Бч)(КЌбЁЬтЩѓХњБэ,ШЮЮёЪщ,ПЊЬтБЈИц,БЯвЕТлЮФЫЕУїЪщ16000зж,Д№БчМЧТМ)
еЊ вЊЃКЫцзХХЉвЕЪ§ОнЕФПьЫйЛ§РлКЭдіГЄЃЌШчКЮРћгУКЃСПЕФХЉвЕЪ§ОнвдЛёШЁПЦбЇЕФХЉвЕжЊЪЖЁЂЙцТЩКЭОіВпжЇГжаХЯЂГЩЮЊЗЧГЃживЊЕФПЮЬтЁЃЪзЯШЃЌБОЮФМђЪіЪ§ОнЭкОђММЪѕдкХЉвЕаХЯЂЭкОђжаЕФИХПіЃЛШЛКѓЃЌЗжЮіСЫЙиСЊЙцдђЕФдРэКЭзїгУЃЌЩюШыЗжЮіAprioriЁЂFP-TreeЕШЫуЗЈЕФЬиЕуЃЛзюКѓЃЌгІгУЕНЭкОђХЉвЕаХЯЂгыХЉвЕВњжЕжЎМфЕФЙиСЊЙиЯЕЃЌжИЕМХЉвЕЩњВњВЂЮЊХЉвЕЩњВњЬсЙЉе§ШЗПЦбЇвРОнМАПЩППЕФОіВпжЇГжЁЃ
ЙиМќДЪЃКЙиСЊЙцдђЃЛAprioriЫуЗЈЃЛХЉвЕаХЯЂЭкОђ
Research on Association Rules Application in Agricultural Information Mining
AbstractЃКAs agriculture data rapidly accumulating and growth, how to use the mass data to obtain scientific agriculture agricultural knowledge, regularity and decision support information becomes very important topic. First of all, this paper briefly describes the data mining technology in the situation of agricultural information mining. Then, the paper analyzes the principle and function of association rules, in-depth analysis of FP-Apriori, algorithms' characteristics such as Tree. Finally, it applies these algorithms to excavate the agriculture information and the relationship between agricultural output, guide agricultural production and to provide the correct for agricultural production and reliable scientific basis for decision support.
KeywordsЃКAssociation rules; Apriori algorithms; Agricultural information mining
2.4 Ъ§ОнЭкОђЕФЙІФм
Ъ§ОнЭкОђЙІФмгУгкжИЖЈЪ§ОнЭкОђШЮЮёжавЊевЕФФЃЪНРраЭЁЃЪ§ОнЭкОђШЮЮёвЛАуПЩЗжЖјСНРрЃКУшЪіКЭдЄВтЁЃУшЪіадЭкОђШЮЮёПЬЛЪ§ОнПтжаЪ§ОнЕФвЛАуЪєадЃЛдЄВтаЭЭкОђШЮЮёдкЕБЧАЪ§ОнЩЯНјааЭЦЖЯЃЌвдНјаадЄВтЁЃ
дкФГжжЧщПіЯТЃЌгУЛЇВЛжЊЕРЪВУДРраЭЕФФЃЪНЪЧгаШЄЕФЃЌвђДЫПЩФмЯыВЂааЕФЫбЫїЖржжВЛЭЌЕФФЃЪНЁЃетОЭашвЊЪ§ОнЭкОђЯЕЭГФмЙЛЭкОђЖржжРраЭЕФФЃЪНЃЌвЛЪЪгІВЛЭЌЕФгУЛЇашЧѓЛђВЛЭЌЕФгІгУЁЃДЫЭтЃЌЪ§ОнЭкОђЯЕЭГгІЕБФмЙЛЗЂЯжИїжжСЃЖШ(МДВЛЭЌЕФГщЯѓВу)ЕФФЃЪНЁЃЪ§ОнЭкОђЯЕЭГгІЕБгІдЪгУЛЇИјГіЬсЪОЃЌжИЕМЛђОлМЏгаШЄФЃЪНЕФЫбЫїЁЃЪ§ОнЭкОђЙІФмвдМАЫќУЧПЩвдЗЂЯжЕФФЃЪНРраЭНщЩмШчЯТЁЃ
2.4.1 ЙиСЊЗжЮі
ЙиСЊЗжЮі(Association Analysis)гУгкЗЂЯжЙиСЊЙцдђЃЌЙиСЊжЊЪЖ(Association)ЗДгГвЛИіЪТМўКЭЦфЫћЪТМўжЎМфЕФвРРЕЛђЙиСЊЁЃЙиСЊЗжЮіЕФФПЕФОЭЪЧевГіЪ§ОнПтжавўВиЕФЙиСЊаХЯЂЁЃЙиСЊПЩЗжЮЊМђЕЅЙиСЊЁЂЪБађЙиСЊЁЂвђЙћЙиСЊЁЂЪ§СПЙиСЊЕШЁЃ
2.4.2 здЖЏдЄВтЧїЪЦЕФааЮЊ
Ъ§ОнЭкОђздЖЏдкДѓаЭЪ§ОнПтжабАевдЄВтадаХЯЂЃЌвдЭљашвЊНјааДѓСПЪжЙЄЗжЮіЕФЮЪЬтШчНёПЩвдбИЫйжБНггЩЪ§ОнБОЩэЕУГіНсТлЁЃвЛИіЕфаЭЕФР§згОЭЪЧЪаГЁдЄВтЮЪЬтЃЌЪ§ОнЭкОђЪЙгУЙ§ШЅгаЙиДйЯњЕФЪ§ОнРДбАевЮДРДЭЖзЪжаЛиБЈзюДѓЕФгУЛЇЃЌЦфЫћПЩдЄВтЮЪЬтАќРЈдЄВтЦЦВњвдМАШЯЮЊЖджИЖЈЪТМўзюПЩФмзіГіЗДгГЕФШКЬхЁЃ
2.4.3 ЗжРрКЭдЄВт
ЗжРр(Classification)КЭдЄВт(Prediction)ЪЧСНжжЪ§ОнЗжЮіаЮЪНЃЌПЩвдгУгкЬсШЁУшЪіживЊЪ§ОнРрЕФФЃаЭЛђдЄВтЮДРДЕФЪ§ОнЧїЪЦЁЃЪ§ОнЗжРрЪЧвЛИіСНВНЕФЙ§ГЬЃЌЕквЛВНЃЌНЈСЂвЛИіФЃаЭЃЌУшЪіИјЖЈЕФЪ§ОнМЏЃЌЭЈЙ§ЗжЮігЩЪєадУшЪіЕФЪ§ОндЖзщРДЙЙдьФЃаЭЃЌетВПЗжЕФЫуЗЈгаЃКОіВпЪї(Decision Tree)ЁЂБДвЖЫЙЗжРрЫуЗЈ(Bayesian Classification)ЁЂКѓЯђДЋВЅЫуЗЈ(Back Propagation)ЁЂK-зюНќСкНќЗжРрЫуЗЈ(K-Nearest Neighbor Classifiers)ЁЂЛљгкАИР§ЕФЭЦРэ(Case-based Reasoning)ЁЂвХДЋЫуЗЈ(Genetic Algorithms)ЁЂДжВкМЏЫуЗЈ(Rough Set Algorithms)ЁЂФЃК§МЏЫуЗЈ(Fuzzy Set Approaches)ЁЂЩёОЭјТчЫуЗЈЕШ(Neural Networks)ЕШЁЃЕкЖўВНЃЌЪЙгУЪ§ОнФЃаЭНјааЗжРр[5]ЁЃ
ЗжРрКЭдЄВтЕФЧјБ№ЪЧЃКгУдЄВтЗЈдЄВтЗжРрБъКХ(РыЩЂжЕ)ЮЊЗжРрЃЌгУдЄВтЗЈдЄВтСЌајжЕ(Р§ШчЪЙгУЛиЙщЗНЗЈ)ЮЊдЄВтЁЃЗжРрКЭдЄВтОпгаЙуЗКЕФгІгУЃЌАќРЈаХгўжЄЪЕЁЂвНСЦеяЖЯЁЂадФмдЄВтКЭбЁдёЙКЮяЕШЁЃ
2.4.4 ОлРрЗжЮі
ОлРр(Clustering)ЪЧНЋЪ§ОнЖдЯѓЗжзщГЩЮЊЖрИіРраЭЛђДиЃЌдкЭЌвЛДижаЕФЖдЯѓжЎМфОпгаНЯИпЕФЯрЫЦЖШЃЌЖјВЛЭЌДижаЕФЖдЯѓВюБ№НЯДѓЁЃгыЗжРрКЭдЄВтВЛЭЌЃЌОлРрВйзївЊЛЎЗжЕФРрЪЧЪТЯШЮДжЊЕФЃЌРрЕФаЮГЩЪЧЪ§ОнЧ§ЖЏЕФЃЌЪєгквЛжжЮожИЕМЕФбЇЯАЗНЗЈЁЃжївЊЕФОлРрЫуЗЈПЩвдЛЎЗжЮЊШчЯТМИРрЃКЛЎЗжЗНЗЈ(Partitioning Method)ЁЂВуДЮЕФЗНЗЈ(Hierarchical Method)ЁЂЛљгкУмЖШЕФЗНЗЈ(Density-based Method)ЁЂЛљгкЭјИёЕФЗНЗЈ(Grid-based Method)ЁЂЛљгкФЃЪНЕФЗНЗЈ(Model-based Method)ЁЃОлРрЗжЮівбОЙуЗКгІгУгкаэЖрЗНУцАќРЈФЃЪНЪЖБ№ЃЌЪ§ОнЗжЮіЃЌЭМЯѓДІРэЃЌвдМАЪаГЁбаОПЕШЁЃ
2.4.5 ЙТСЂЕуЗжЮі
Ъ§ОнПтжаПЩФмАќКЌвЛаЉЪ§ОнЖдЯѓЃЌЫќУЧгыЪ§ОнЕФвЛАуааЮЊЛђФЃаЭВЛвЛжТЁЃетаЉЪ§ОнЖдЯѓЖдГЦЮЊЙТСЂЕу(Outlier),ДѓВПЗжЪ§ОнЭкОђЗНЗЈНЋЙТСЂЕуЪгЮЊдыЩљЛђвьГЃЖјЖЊЪЇЁЃШЛЖјдквЛаЉгІгУжа(ШчЦлЦМьВт)ЃЌЙТСЂЕуЪТМўПЩФмБШНЯе§ГЃГіЯжЕФЪТМўИќгаШЄЃЌЙТСЂЕуЪ§ОнЗжЮіГЦзїЙТСЂЕуЭкОђЁЃЛљгкМЦЫуЛњЕФЙТСЂЕуЬНВтЗНЗЈЗжЮЊШ§РрЃКЛљгыЭГМЦЕФЙТСЂЕуМьВт(Statistics-based Outlier Detection)ЁЂЛљгкОрРыЕФЙТСЂЕуМьВт(Distance-based Outlier Detecion)ЁЂЛљгкЦЋРыЕФЙТСЂЕуМьВт(Deviation-base Outlier detection)ЁЃЙТСЂЕуЗжЮіПЩвдЗЂЯжаХгУПЈЦлЦЁЃЭЈЙ§МьВтвЛИіИјЖЈеЪКХгые§ГЃЕФИЖЗбЯрБШЃЌвдИЖПюЪ§ЖюЬиБ№ДѓРДЗЂЯжаХгУПЈЦлЦадЪЙЭЌЁЃЙТСЂЕужЕЛЙПЩвдЭЈЙ§ЙКЮяЕиЕуКЭРраЭЃЌЛђЙКЮяЦЕТЪРДМьВтЁЃ
2.4.6 бнБфЗжЮі
Ъ§ОнбнБфЗжЮі(Evolution Analysis)УшЪіааЮЊЫцЪБМфБфЛЏЕФЖдЯѓЕФЙцТЩЛђЧїЪЦЃЌВЂЖдЦфНЈФЃЁЃОЁЙметжжЗжЮіПЩФмАќКЌЪБМфЯрЙиЪ§ОнЕФЬиеїЛЏЁЂЧјЗжЁЂЙиСЊЁЂЗжРрЛђОлРрЃЌетРрЗжЮіЕФВЛЭЌЬиЕуАќКЌЪБМфађСаЪ§ОнЗжЮіЁЂађСаЛђжмЦкФЃЪНЦЅХфКЭЛљгкРрЫЦадЕФЪ§ОнЗжЮі[6]ЁЃ
ФП ТМ
еЊвЊ 1
ЙиМќДЪ 1
1 ЧАбд 2
2 Ъ§ОнЭкОђИХЪі 2
2.1 Ъ§ОнЭкОђЕФМђНщ 2
2.2 Ъ§ОнЭкОђЕФбаОПЯжзД 2
2.3 Ъ§ОнЭкОђЕФЙ§ГЬ 3
2.4 Ъ§ОнЭкОђЕФЙІФм 4
2.4.1 ЙиСЊЗжЮі 4
2.4.2 здЖЏдЄВтЧїЪЦЕФааЮЊ 4
2.4.3 ЗжРрКЭдЄВт 4
2.4.4 ОлРрЗжЮі 5
2.4.5 ЙТСЂЕуЗжЮі 5
2.4.6 бнБфЗжЮі 5
3 ЙиСЊЙцдђЕФИХЪі 5
3.1 ЙиСЊЙцдђЕФЖЈвх 6
3.2 ЙиСЊЙцдђЪєадЕФЫФИіВЮЪ§ 6
3.2.1 жЇГжЖШ(Support) 6
3.2.2 ПЩаХЖШ(Confidence) 6
3.2.3 ЦкЭћПЩаХЖШ(Expected Confidence) 7
3.2.4 зїгУЖШ(Lift) 7
3.3 ЙиСЊЙцдђЕФЗжРр 7
3.4 ЙиСЊЙцдђЕФЭкОђВНжш 8
4 ЙиСЊЙцдђЕФЭкОђЫуЗЈ 8
4.1 ВМЖћаЭЙиСЊЙцдђЕФЭкОђ 8
4.2 ЖрВуЙиСЊЙцдђЕФЭкОђ 8
4.3 ЖрЮЌЙиСЊЙцдђЕФЭкОђ 8
5 ЫуЗЈНщЩмМАЪЕЯж 9
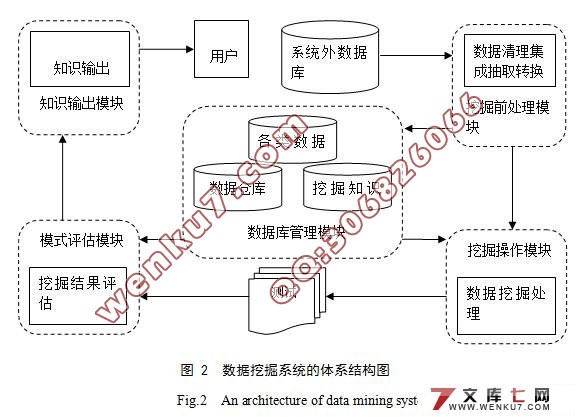
5.1 Ъ§ОнЭкОђЕФЬхЯЕНсЙЙ 9
5.1.1 Ъ§ОнПтЙмРэФЃПщгыЭкОђЧАДІРэФЃПщ 9
5.1.2 ФЃЪНЦРЙРФЃПщЁЂжЊЪЖЪфГіФЃПщвдМАЭкОђВйзїФЃПщ 9
5.2 ЫуЗЈНщЩмМАЪЕЯж 10
5.2.1 AprioriЫуЗЈМђНщ 10
5.2.2 AprioriЫуЗЈЕФзщГЩ 10
5.2.3 AprioriЫуЗЈЕФЪЕЯж 11
5.2.4 FP-treeЫуЗЈМђНщ 15
5.2.5 ЭкОђFP-treeЕФжївЊВНжш 16
5.2.6 FP-treeЫуЗЈгыAprioriЫуЗЈЕФБШНЯ 19
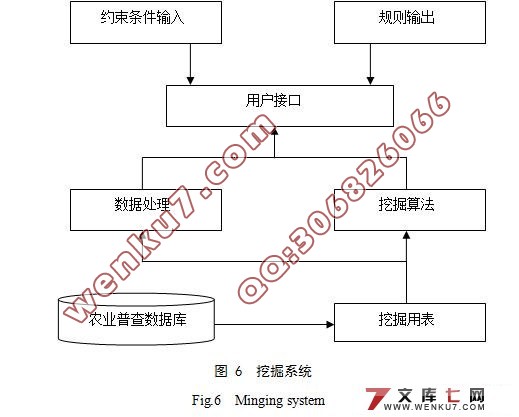
6 ЛљгкХЉвЕЦеВщЪ§ОнПтЕФЪ§ОнЭкОђЯЕЭГ 20
6.1 УцСйЕФЮЪЬт 20
6.2 НтОіЗНЗЈ 21
6.3 Ъ§ОнЭкОђЯЕЭГ 21
6.4 Ъ§ОндЄДІРэ 22
6.5 ЪЕМЪгІгУ 23
7 НсТл 25
ВЮПМЮФЯз 26
жТ аЛ 27
|
