毕业设计文档相似度判别算法的研究与实现
来源:wenku7.com 资料编号:WK79880 资料等级:★★★★★ %E8%B5%84%E6%96%99%E7%BC%96%E5%8F%B7%EF%BC%9AWK79880

资料介绍
| 摘 要:毕业设计是大学生高校学习中最为重要的课程之一,是对四年学习的完整的总结。毕业设计相关文档中的雷同现象是毕业设计的一大痼疾,要查找出文档中存在的雷同现象会浪费大量的资源。 本课题主要针对毕业设计文档评语中存在的雷同现象进行了相似度判别算法的研究。利用中文分词技术、VSM文本分类技术的原理,将单词ID向量和单词词频向量的简单向量夹角计算作为算法的基础,结合文档的全文搜索,设计出判别算法,计算出文档的相似度,并根据算法的研究成果,使用asp.NET技术设计出可以对文档的评语进行相似度判别的系统原型。 通过对系统研究和试验可以得出,该系统对较短的文档可以完成大多数情况的雷同判定,能够在一定程度上满足对毕业设计文档的评语进行相似度判别的要求。但算法和系统尚存在一些问题,在判定的准确率上仍需提高,需要通过不断的试验来进行改进。 毕业设计(论文)外文摘要 Abstract: Graduation thesis is one of the most important courses of the collage students. It is a complete summary of the four-year study. The similarity phenomenon on graduation documents is a big problem for graduation thesis. It will waste a lot of resources to find out the similarities of the documents. The aim of this study is to find out the similar comments in the graduation documents. This algorithm based on Chinese lexical analysis technology and VSM text classification technology, and the elements of this algorithm is to calculate the cosine of two word identity vector or word frequency vector. With the full text search, the algorithm can get the similarity of two documents. Finally, the prototype of similarity judgment system has been designed with asp.NET technology. Through research and test on the system, the system can be implied on shorter document in most cases, and it can meet most of the request for judging the document similarity. However, the algorithm and system still has lots of shortcomings, the accuracy need to be improved. More work will be done to improve this study. 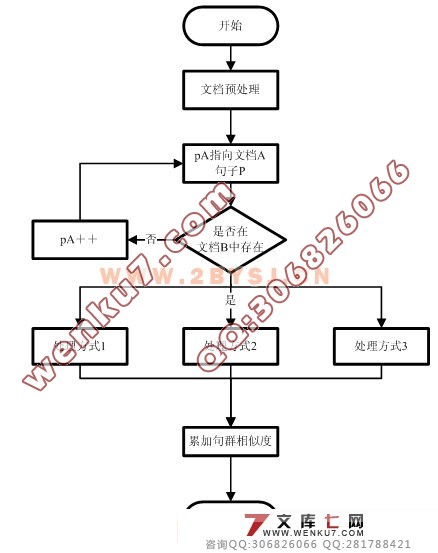 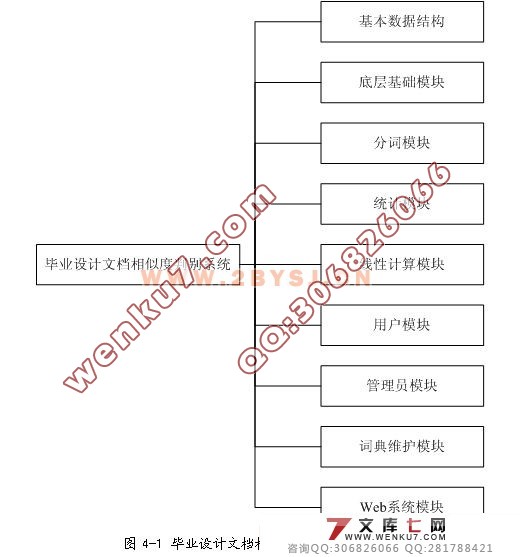   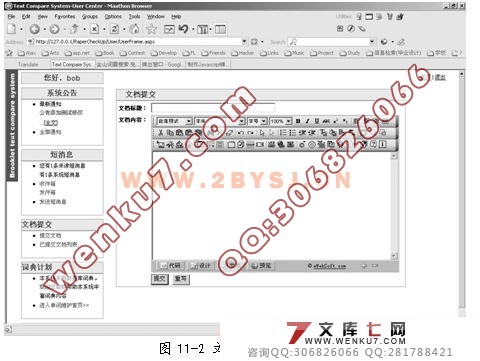 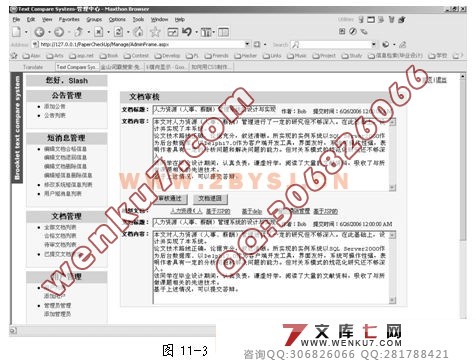 目 录 1 引言 1 1.1 课题的研究背景与意义 1 1.1.1 课题的研究背景 1 1.1.2 课题的研究意义 1 1.2 问题定义与研发目标 2 1.2.1 问题的定义 2 1.2.2 研发的目标 2 1.3 课题的调研 3 1.4 可行性分析 4 1.4.1 技术可行性 5 1.4.2 经济可行性 5 1.4.3 操作可行性 6 1.5 论文各章简介 6 2 需求分析 8 2.1 业务流分析 8 2.1.1 概念描述 8 2.2.2 课题业务流描述 8 2.1.3 业务流图 9 2.2 数据流分析 10 2.3 数据字典 13 2.3.1 数据流 13 2.3.2 数据流分量(部分) 14 2.3.3 数据存储 16 2.3.4 处理 16 3 文本比对算法描述 19 3.1 文本比对算法描述 19 http:// 3.2 文本比对算法清单 22 4 系统设计 26 4.1 系统设计原则 26 4.2 系统设计要点 26 4.3 系统总体结构设计 26 4.4 系统数据库设计 28 4.4.1 数据库E-R关系图 28 4.4.2 数据库关系模式 29 4.4.3 数据库关系表 29 4.5 系统输入输出设计 31 4.6 开发环境和开发工具设计 32 5 基本数据结构详细设计 33 5.1 向量Vector设计 33 5.1.1 Vector功能介绍 33 5.1.2 类成员 33 5.2 矩阵Matrix设计 33 5.2.1 Matrix功能介绍 33 5.2.2 类成员 33 5.3 词典Dictionary设计 34 5.3.1 Dictionary功能介绍 34 5.3.2 类成员 34 5.4 单词属性WordProperty设计 35 5.4.1 WordProperty功能介绍 35 5.4.2 类成员 35 6 数据库、控件底层详细设计 37 6.1 数据库操作底层设计 37 6.1.1 数据库操作底层简介 37 6.1.2 数据库操作底层结构 37 6.2 控件操作底层设计 39 6.2.1 控件操作底层简介 39 6.2.2 控件库操作底层结构 39 7 分词模块详细设计 41 7.1 分词模块功能简介 41 7.2 分词模块体系结构 41 7.3 分词模块核心算法说明 41 8 统计模块详细设计 44 8.1 统计模块功能简介 44 8.2 统计模块体系结构 44 8.3 统计模块设计说明 44 9 线性计算模块详细设计 46 9.1 线性计算模块功能简介 46 9.2 线性计算模块体系结构 46 9.3 线性计算模块设计说明 46 10 文档相似判别系统详细设计 47 10.1 系统界面风格设计 47 10.2 系统主要结构设计 47 10.3 系统用户端设计 48 10.4 系统管理员模块设计 49 10.5 词典维护模块设计 50 11 用户手册 51 11.1 系统功能简介 51 11.2 系统运行环境 51 11.3 系统安装 51 11.4 系统使用说明 51 12 系统评价 55 12.1 系统的优点 55 12.2 系统的问题及改进方案 55 12.3 设计的心得与体会 56 结 论 58 致 谢 59 参 考 文 献 60 1 引言 毕业设计是大学生在校学习非常重要的一个环节,是对高校人才培养质量的一次检阅。通过毕业设计的锻炼,能全面提高学生综合运用知识的能力,毕业生和指导教师必须按照严格的规范来开展毕业设计工作。毕业论文质量是国家本科教学水平评估中一项重要考核指标,在毕业设计文档管理过程中,对毕业设计相关文档的检查,特别是毕业设计论文评语雷同现象的检查,通过人工完成是非常繁重和低效的,迫切需要利用计算机来帮助人们完成这种繁琐、乏味的工作。 1.1 课题的研究背景与意义 1.1.1 课题的研究背景 在毕业设计过程中,需要提交的文档一般有:选题审题表、任务书、开题报告、外文资料翻译、期中检查表、毕业设计(论文)说明书、各个文档的评语以及毕业设计的审核表格等。在毕业设计文档的检查工作中,总是或多或少的发现一些雷同的文档,而为了检查出这少部分的文档,总是需要花费不对称的时间来对所有的设计文档进行检查。负责文档审核的老师在检查过程中总是要面对大量的文档,工作相当的繁重,而且人工校对效率非常低下,同时在检查中也会因为疲劳等原因出现很多疏漏。 严格的文档管理对学生认真进行毕业设计、指导老师认真指导都是一种督促。定期的对设计过程中提交的各种文档进行评估和检查是一种很好的规范毕业设计的方式。而人工的校对与检查繁重且枯燥,特别的对于检查设计中最为恶劣的抄袭行为更是劳民伤财。本课题的目标就是代替人工检查,针对最为尖锐的文档雷同现象,使用计算机的能力来辅助老师检查相关的文档与评语的雷同现象,以提高劳动生产率并减轻工作量。 对于文档相似度的判定,从理论上分类属于文本分类的问题。自90年代以来,众多的统计方法和机器学习方法应用于自动文本分类。文本分类技术的研究引起了研究人员的极大兴趣。当前英文自动分类已经取得了丰硕的成果,提出了多种成熟的分类方法,如最近邻分类、贝叶斯分类、决策树方法以及基于支持向量机(SVM)、向量空间模型(VSM)、回归模型和神经网络等方法,但对于中文文本的自动分类技术研究尚不尽人意。目前国内中文文本分类研究主要集中在朴素贝叶斯、向量空间模型和支持向量机等技术上。本课题将在这些研究的基础上进行一些研究和设计。 1.1.2 课题的研究意义 首先,对毕业设计文档的校对工作对老师的耐心是一种考验。论文指导教师对自己指导的学生的文档进行检查,相对而言还是具有一定的操作性的,但是将检查的范围扩大到本系所有的文档,进行文档检查就非常困难了。短时间内阅读大量的文档,记忆文档的要点,是非常乏味和枯燥的工作,对老师的工作积极性是一个很大的打击,应付交差的心理便会滋生,毕业设计文档的质量也就不能够很好的控制了。使用计算机辅助检查,便会克服这些存在的问题,并对那些存在侥幸心里的人起到一定的震慑作用。 其次,作为人工劳动的替代,文档相似度判别系统提高了文档检查的劳动生产率,减轻了老师的工作压力,这样对毕业设计的质量控制有了一定的保障,对毕业设计工作起到一定的辅助作用。 文档相似度判别算法本质上是一种文本分类算法。作为一种文本分类算法,文档相似度判别的研究对于进一步的去研究中文的文本处理等算法是一个很好的开始,并且能够打下良好的基础。作为在国内刚刚开始起步的中文文本分类的研究,涉足这方面的研究可以保持同国内的同步位置,取得国内领先也不是什么不可能的事情。 文档相似度判别算法以及这个思路的最大的应用除了判定文章的雷同程度之外,在考试系统的自动阅卷功能中,对雷同卷进行检查,为考试的自动化提供了一种新的思路和方式;对于考场试卷的雷同判定也就可以做到比较迅速和准确了。 文档相似度判别算法和文档分类是人工智能在信息检索领域的中的一个重要的应用,也是当前在人工智能和信息检索这两个学科中研究的热门方向。这些内容的学习和研究,为提高自身水平和赶超领先水平具有重要意义。 1.5 论文各章简介 第一章是引言部分。引言主要论述本课题的研究背景和意义,对文本相似度判别这个问题进行了定义,列举了在问题调研过程中设计的问题和案例;最后从技术上、经济上和可操作性上对本课题的可行性进行了分析。 第二章是需求分析部分。首先对该系统的业务进行了详细的分析,然后根据业务流进行数据流分析,并构建了顶级数据流图、I级数据流图和各部分的数据流图;给出了数据字典中的数据流、数据流分量、数据存储和处理。 第三章详细描述了文本相似度判别的算法。通过对雷同文本的分析给出了本课题的适用范围,并且对文本的相似度判定给出了一个明确的算法。 第四章进行系统总体设计。分别进行了系统要点设计、系统总体结构设计、系统数据库设计、系统输入输出设计、系统开发环境和开发工具设计,给出了系统的模块划分、数据库设计方案,以及文档输入方式和输出结果方案。 第五章对设计中的基本的数据结构进行了描述。介绍了在设计中构造的Vector、Matrix、Dictionary和WordProperty的方法和属性,并对其中涉及的算法进行了详细的介绍。 第六章是底层模块的介绍。这个模块分为数据库操作模块和控件绑定模块。数据库操作模块提供了一些方法,它们对数据库操作进行了封装;控件绑定模块也提供了很多对控件绑定的方法。这些方法的提供大大方便了设计的进行。 第七章介绍了系统分词功能的实现。介绍了分词模块的结构以及相关的接口,并对去除标记html代码和最大前项分词这两个重点算法进行了详尽的描述,并给出了对这两个算法的评价。 第八章介绍了统计功能模块的作用。描述了当前统计功能模块的结构和主要功能,并对该模块的改进提出了方案。 第九章对线性计算单元模块进行了描述。该模块提供了进行Vector计算的功能,同样给出了该模块改进的方案,以使这个模块具有更加强大的功能。 第十章给出了演示系统的设计说明。对于该系统,根据使用方式划分成了普通用户、管理员用户、短消息通信、词典维护等功能模块,在本章节对这些模块的功能进行了描述,并给出了页面的设计方案。 第十一章是演示系统的用户手册。该章节对整个系统的功能和原理进行了简单的介绍,给出了系统运行的基本平台和系统配置要求,然后给出了安装办法。最后使用图片配合描述的方式对系统的操作方法进行了介绍。 第十二章对系统进行各方面的评价。首先指出了这个系统在设计上具有灵活性和可扩充性等的优点;然后对本课题中提出的算法进行了进一步的讨论,并针对讨论中的问题提出了一些简单的解决方案,最后讲述了自己在设计过程中的心得与体会。 |